Northwestern University researchers, in collaboration with Tilde Research and the University of Washington, have introduced ‘Parallax,’ a new parameterized Local Linear Attention mechanism that refines the core Transformer architecture. This novel approach deliberately retains the long-standing softmax attention, opting instead to enhance its capabilities with a learned covariance correction branch. Parallax is designed to scale effectively for large language model (LLM) pretraining and is specifically codesigned to integrate with the Muon framework. This development marks a significant departure from conventional efficiency efforts that typically seek to replace softmax attention, offering a fresh perspective on optimizing computational performance for advanced AI models.
Key Developments
- Parallax introduces a parameterized Local Linear Attention (LLA) that builds upon existing LLA principles, treating attention as a regression solver.
- Unlike most efficiency efforts, Parallax maintains the traditional softmax attention mechanism within the Transformer architecture.
- The core innovation involves adding a learned covariance correction branch to the softmax attention, enhancing its predictive power.
- This new mechanism is engineered to scale for large language model pretraining, indicating its relevance for next-generation AI development.
- Parallax focuses on making added computational steps more efficient on modern GPUs rather than solely reducing raw compute.
What Happened
A team of researchers from Northwestern University, Tilde Research, and the University of Washington recently unveiled ‘Parallax,’ a novel attention mechanism for Transformer models. This new system, detailed in a new paper, represents a distinct evolution of the attention architecture that has remained largely unchanged since its inception in 2017. Instead of pursuing the common strategy of replacing softmax attention altogether for efficiency gains, Parallax integrates a sophisticated correction branch directly onto the existing softmax framework.
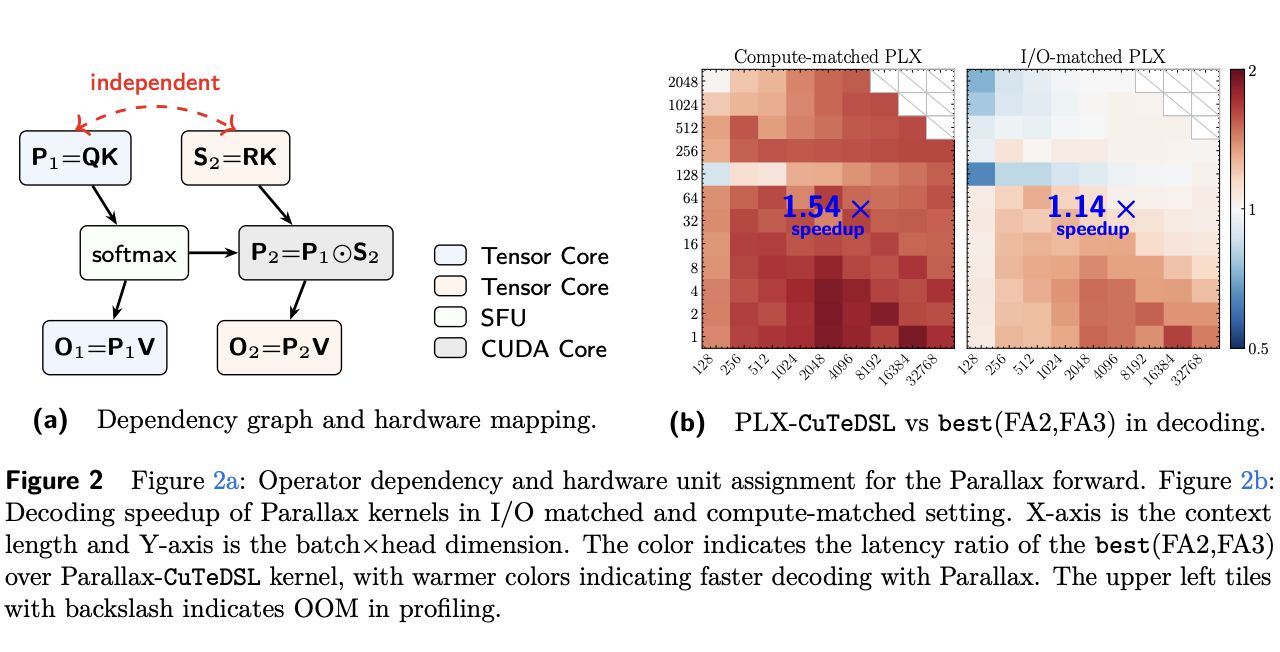
Parallax builds upon the foundation of Local Linear Attention (LLA), which interprets the attention process as a regression solver operating over key-value pairs. In this framework, keys function as training data points, values as their corresponding labels, and the query acts as the test point. Traditional softmax attention is understood as a nonparametric estimator, specifically the Nadaraya-Watson estimator, which fits a local constant function for each query, effectively determining how much each key-value pair contributes to the output based on proximity to the query.
The innovation with Parallax lies in its deliberate addition of compute, specifically through a learned covariance correction branch, which then undergoes optimization to run more efficiently on contemporary GPU architectures. This strategic choice contrasts with most research in Transformer efficiency, which often prioritizes reducing the total number of operations. By enhancing, rather than replacing, the established softmax attention, Parallax aims to improve the predictive accuracy and robustness of attention mechanisms, particularly for demanding tasks like large language model pretraining, and is designed to work in conjunction with the Muon framework.
Why It Matters
The introduction of Parallax is significant because it challenges the prevailing wisdom in Transformer architecture optimization. For years, the focus has been on finding alternatives to softmax attention, primarily due to its quadratic computational complexity with respect to sequence length. By retaining softmax and augmenting it, Parallax suggests that there might be untapped potential in refining existing, proven mechanisms rather than always seeking radical overhauls.
This approach could lead to more stable and robust attention mechanisms for large language models, which are increasingly critical across various industries. The ability to scale Parallax for LLM pretraining means it could influence the development of future foundational models, potentially offering a path to models that are both powerful and computationally feasible. It signals a shift in thinking about efficiency, moving beyond mere compute reduction to include making existing computations more GPU-friendly.
The research also highlights the ongoing innovation in fundamental AI components, even those considered mature. It underscores that even core building blocks like attention can be re-evaluated and improved upon, potentially leading to performance gains that are difficult to achieve through model scaling alone. For AI developers and researchers, this means new avenues for exploration in model design and optimization.
Industry Impact
Parallax’s novel approach to attention could have a ripple effect across the AI industry, particularly for companies heavily invested in large language models and advanced deep learning. Enterprises that develop or deploy LLMs for applications ranging from customer service chatbots to complex scientific simulations stand to benefit from more efficient and potentially more accurate attention mechanisms. The inherent stability of building on softmax, combined with targeted improvements, could reduce the risks associated with deploying entirely new, untested attention variants.
For cloud providers and hardware manufacturers, the emphasis on making computations cheaper to run on modern GPUs is particularly relevant. If Parallax gains traction, it could influence future GPU design and optimization strategies, encouraging hardware advancements that specifically cater to its computational patterns. This co-design philosophy, where software and hardware evolve in tandem, is crucial for maximizing performance in high-compute AI tasks.
Furthermore, the academic and research communities will likely scrutinize Parallax, potentially inspiring a new wave of research into hybrid attention mechanisms. Instead of a binary choice between softmax and its replacements, researchers might explore more nuanced integrations and enhancements. This could accelerate progress in areas like long-context window processing and multimodal AI, where efficient and effective attention is paramount.
Expert Analysis
The introduction of Parallax represents a sophisticated evolution in Transformer architecture, moving beyond the often-simplistic pursuit of replacing softmax attention with linear approximations. By choosing to augment softmax with a learned covariance correction branch, the researchers are tapping into the inherent strengths of Nadaraya-Watson estimation while addressing its limitations. This approach acknowledges that softmax, despite its computational cost, offers a powerful non-parametric estimation that captures complex relationships in data, a property that many linear approximations struggle to fully replicate.
The key insight here is not just about adding compute, but about adding deliberate compute that can then be optimized for modern hardware. This reflects a growing understanding in the AI community that raw FLOPs are not the only metric; how those FLOPs are executed on specific hardware matters immensely. The co-design with Muon further emphasizes this holistic approach, suggesting a future where attention mechanisms are not standalone components but are optimized within a broader computational framework.
This development could also signal a maturation in AI research, where the focus shifts from purely theoretical breakthroughs to more practical, engineering-centric innovations that improve the real-world performance and deployability of models. For organizations building and deploying large-scale AI, a method that promises better performance without completely reinventing the wheel could be highly attractive, potentially reducing integration challenges and accelerating time to market for new capabilities.
Competitive Landscape
The competitive landscape for attention mechanisms is robust, with numerous research groups and companies vying for more efficient and effective solutions. Major players like Google, OpenAI, and Meta consistently explore alternatives to traditional softmax attention, often focusing on linear attention variants, sparse attention, or recurrence-based mechanisms to address the quadratic scaling problem. For instance, efforts like Perceiver IO from DeepMind or various sparse attention patterns aim to reduce computational load by limiting the number of interactions between tokens.
However, Parallax carves out a unique niche by not entirely abandoning softmax. This contrasts with approaches that aim for full replacement, such as various linear attention models that trade some expressivity for significant speed-ups. The strategy of augmenting softmax rather than replacing it positions Parallax as a potential middle ground, offering the benefits of softmax’s expressive power while mitigating its computational drawbacks through targeted optimization. If Parallax proves to deliver superior performance for LLM pretraining, it could influence how these larger players approach their own attention mechanism research, potentially leading to a diversification of strategies beyond pure efficiency plays.
Future Implications
Near-term (3-6 months): We can expect increased academic scrutiny and implementation efforts of Parallax within the research community. Early adopters in academic labs and potentially some industry research divisions will likely integrate Parallax into experimental LLM architectures to validate its scaling properties and performance benefits, particularly when codesigned with Muon.
Medium-term (1-2 years): If initial benchmarks are positive, major AI development organizations might begin incorporating Parallax or similar hybrid attention mechanisms into their internal LLM pretraining pipelines. This could lead to a new generation of foundational models that exhibit improved accuracy or efficiency profiles compared to purely softmax-based or purely linear-based predecessors. Hardware manufacturers might also begin to subtly optimize their GPU architectures for the specific computational patterns introduced by Parallax.
Long-term (3-5 years): Parallax could establish a new design paradigm for attention mechanisms, where augmentation and optimization of existing robust components become as important as radical invention. This might lead to a more nuanced understanding of the trade-offs between expressivity, efficiency, and hardware compatibility, fostering a richer ecosystem of specialized attention mechanisms tailored for different AI tasks and computational environments.
Actionable Insights
- Monitor Research Benchmarks: Keep a close watch on published benchmarks and academic papers evaluating Parallax’s performance, especially its scaling capabilities for large models and its integration with the Muon framework.
- Evaluate Hybrid Attention Strategies: For organizations developing custom Transformer models, explore the feasibility of hybrid attention mechanisms that combine the strengths of softmax with targeted linear or correction branches, rather than defaulting to full replacement.
- Engage with Hardware Optimizations: If working with custom hardware or cloud infrastructure, investigate how Parallax’s computational patterns align with current GPU architectures and consider potential optimizations for its specific workload.
- Consider Foundational Model Impact: Developers of downstream AI applications should anticipate potential improvements in the capabilities of future LLMs that might incorporate Parallax, leading to more robust or efficient base models.
- Participate in Open-Source Implementations: For researchers and engineers, contribute to or experiment with open-source implementations of Parallax to gain hands-on experience and contribute to its development and validation.
What is Parallax in AI?
Parallax is a new parameterized Local Linear Attention (LLA) mechanism for Transformer models. It enhances the traditional softmax attention by adding a learned covariance correction branch, aiming to improve efficiency and performance for large language model pretraining.
How does Parallax differ from other attention mechanisms?
Unlike many recent efforts that seek to replace softmax attention for efficiency, Parallax retains softmax attention and augments it with a correction branch. It focuses on making added computations cheaper on modern GPUs rather than solely reducing total compute.
Who developed Parallax?
Parallax was developed by a collaborative team of researchers from Northwestern University, Tilde Research, and the University of Washington. Their work introduces a novel approach to optimizing Transformer attention.
What is the significance of Parallax for LLMs?
Parallax is designed to scale to large language model pretraining, suggesting it could enable more accurate and efficient foundational models. Its approach could lead to more stable and robust attention mechanisms for next-generation AI.
Does Parallax eliminate softmax attention?
No, Parallax deliberately keeps softmax attention. Its innovation lies in bolting on a correction branch to enhance softmax’s capabilities, rather than replacing it entirely, offering a refined approach to attention mechanism design.
Key Takeaways
- Parallax introduces a novel parameterized Local Linear Attention that augments, rather than replaces, the traditional softmax attention mechanism.
- The core innovation is a learned covariance correction branch designed to improve attention performance while being optimized for modern GPUs.
- This new approach challenges conventional wisdom in Transformer efficiency, focusing on making computations cheaper to run rather than solely reducing compute.
- Parallax is specifically engineered to scale effectively for large language model pretraining and is codesigned with the Muon framework.
- The development signifies a potential shift towards hybrid attention mechanisms that combine the strengths of existing techniques with targeted enhancements.















