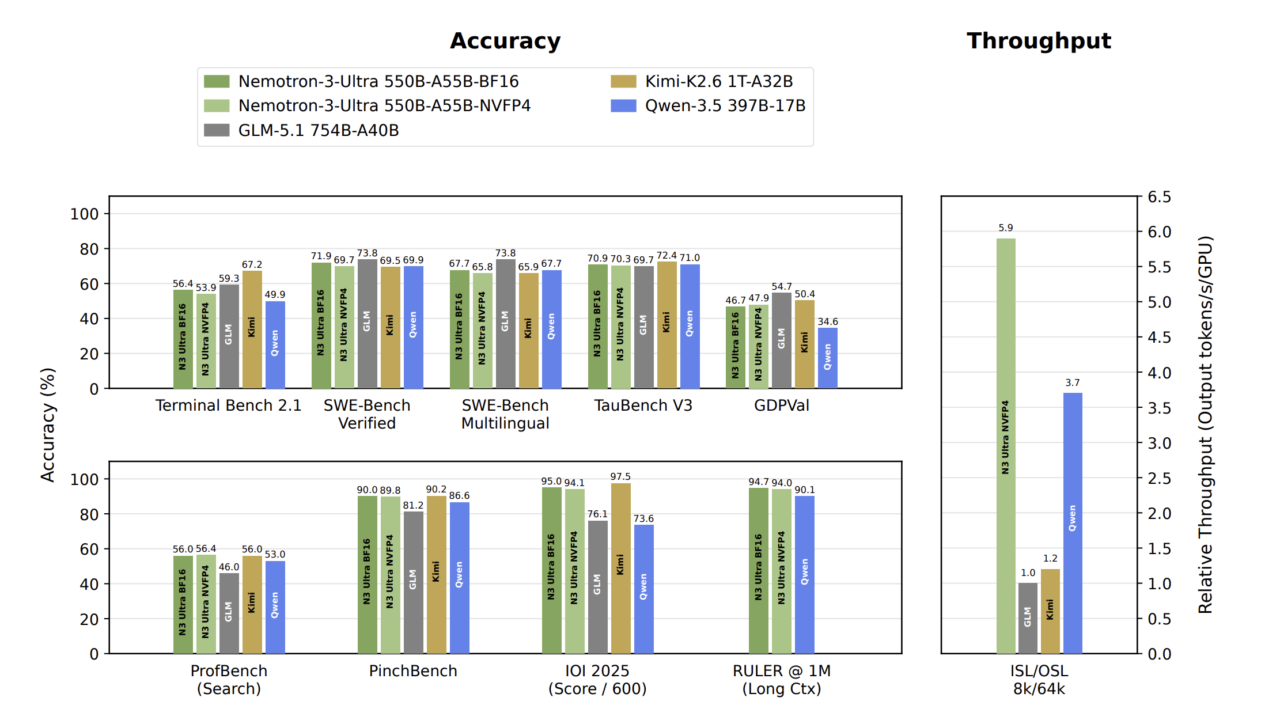
NVIDIA has unveiled Nemotron 3 Ultra, the most expansive model within its Nemotron 3 series, engineered specifically to address the complexities of long-running AI agents. This 550 billion total parameter Mixture-of-Experts (MoE) model is designed to sustain high accuracy while significantly reducing the computational overhead associated with extended inference tasks. Its introduction marks a strategic move to optimize the performance and cost efficiency for AI systems that engage in multi-turn planning, tool invocation, and complex reasoning. The model’s unique architecture, combining Mamba and Attention mechanisms, represents a notable departure from pure Transformer designs, offering a potential solution to the escalating token counts and inference costs faced by advanced agentic AI applications.
Key Developments
- NVIDIA released Nemotron 3 Ultra, a 550 billion total parameter Mixture-of-Experts (MoE) model, as the largest in its Nemotron 3 family.
- The model is specifically engineered to enhance the efficiency and accuracy of long-running AI agents that perform multi-turn planning and tool use.
- Nemotron 3 Ultra features a hybrid Mamba-Attention architecture, moving away from pure Transformer designs to manage long sequences more effectively.
- Only 55 billionactive parameters per token are utilized in its MoE design, aiming to improve accuracy per active parameter.
- The model underwent extensive pre-training on 20 trilliontext tokens, with its context subsequently extended to 1 milliontokens.
What Happened
NVIDIA recently announced the launch of Nemotron 3 Ultra, its latest and most formidable large language model, positioned as the flagship of the Nemotron 3 series. This new offering is a 550 billiontotal parameter MoE model, a significant scale designed to tackle the persistent challenge of maintaining performance and managing costs for AI agents engaged in prolonged, complex interactions. The core problem Nemotron 3 Ultra seeks to solve is the escalating inference cost and potential accuracy degradation that occurs as AI agents operate over many turns, accumulating vast numbers of tokens.
The model’s architecture is a key differentiator, employing a Mixture-of-Experts (MoE) approach where only 55 billionparameters are active per token. This design choice is intended to boost accuracy relative to the active computational load. Furthermore, Nemotron 3 Ultra integrates a hybrid Mamba-Attention architecture, diverging from the conventional pure Transformer models. This hybrid approach leverages Mamba layers for efficient handling of long sequences with sub-quadratic scaling, while retaining a select number of Attention layers to ensure precise recall over extensive contexts.
The development of Nemotron 3 Ultra involved a rigorous training regimen. It was initially pre-trained on an immense dataset of 20 trilliontext tokens, establishing a robust foundational understanding. Following this, its context window was expanded to an impressive 1 milliontokens, enabling it to process and reason over significantly larger inputs. The model then underwent post-training through a combination of Supervised Fine-Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher methods, refining its capabilities for complex agentic tasks.
Why It Matters
The introduction of Nemotron 3 Ultra by NVIDIA carries substantial implications for the AI industry, particularly for developers and enterprises building sophisticated AI agents. Its focus on optimizing long-running agent performance directly addresses one of the most pressing challenges in contemporary AI: the trade-off between an agent’s operational longevity and its economic viability. As AI agents move beyond simple query-response systems to complex, multi-step tasks like automated customer service, research assistance, or code generation, the ability to maintain accuracy and control inference costs becomes paramount.
For businesses, this translates into the potential for more reliable and cost-effective deployment of advanced AI applications. Agents that can plan, call various tools, and reason over extended interactions without significant performance decay or prohibitive costs unlock new possibilities for automation and intelligent assistance. The hybrid Mamba-Attention architecture is particularly noteworthy, suggesting a path forward for managing the computational demands of ever-growing context windows without sacrificing the nuanced understanding that attention mechanisms provide. This innovation could accelerate the development of truly autonomous and capable AI systems.
Head-to-Head Comparison
| Feature | NVIDIA Nemotron 3 Ultra | Traditional Large Transformer Models |
|---|---|---|
| Pricing | Aims for lower inference cost for long sequences | Higher inference cost for long sequences due to quadratic scaling |
| Performance | High accuracy for long-running agents; hybrid architecture for efficiency | High accuracy, but performance can degrade with very long contexts due to cost/latency |
| Best For | Long-running AI agents, complex multi-turn reasoning, tool use | General-purpose language generation, shorter interactions, fine-tuning for specific tasks |
| Key Strength | Efficient handling of extended contexts via hybrid Mamba-Attention, MoE parameter efficiency | Established performance on diverse tasks, broad community support, extensive research |
| Main Weakness | New architectural complexity might require specialized optimization | Computational intensity and cost for extremely long context windows |
Industry Impact
NVIDIA’s Nemotron 3 Ultra is poised to significantly influence several sectors within the broader AI and technology ecosystem. Its specialized design for long-running agents directly benefits industries requiring persistent, intelligent automation. Consider customer service platforms, where agents need to maintain context over lengthy conversations, retrieve complex information, and orchestrate multiple backend systems. Nemotron 3 Ultra’s ability to manage 1 milliontokens of context could drastically improve the coherence and effectiveness of such virtual assistants, leading to more satisfactory customer interactions and reduced operational costs for companies.
In software development and engineering, AI agents are increasingly used for code generation, debugging, and project management. An agent capable of tracking an entire codebase or project specification over many hours, while invoking various development tools, would represent a substantial leap. Nemotron 3 Ultra’s architecture could enable developers to create more sophisticated AI pair programmers or automated QA agents, thereby accelerating development cycles and enhancing code quality. Furthermore, in research and scientific discovery, agents that can parse vast amounts of literature, synthesize findings, and propose experimental designs could see a significant boost in their capabilities.
The model’s Mixture-of-Experts (MoE) design, activating only 55 billionparameters per token out of a total of 550 billiontotal parameters, also signals a broader industry trend towards more efficient large language models. This approach could inspire other model developers to explore similar sparsity techniques, aiming to deliver high performance without the prohibitive computational footprint of fully dense models of similar scale. The hybrid Mamba-Attention structure, by addressing the quadratic scaling issues of pure Attention for long sequences, offers a blueprint for future architectural innovations that prioritize both efficiency and contextual depth.
✓ Pros
- Optimized for long-running AI agents, reducing inference costs over time.
- Hybrid Mamba-Attention architecture efficiently handles very long context windows.
- Mixture-of-Experts design improves accuracy per active parameter, enhancing efficiency.
- Extensive pre-training on 20 trilliontext tokens ensures a robust foundation.
- Context window extended to 1 milliontokens for deep contextual understanding.
✗ Cons
- Complexity of hybrid architecture might present integration challenges for some developers.
- Specific performance benchmarks against established models are yet to be fully detailed.
- Requires significant computational resources for initial deployment and fine-tuning.
- The novelty of Mamba integration may mean a steeper learning curve for optimization.
Analysis
NVIDIA’s launch of Nemotron 3 Ultra signifies a strategic move to solidify its position not just as a hardware provider, but as a crucial enabler of advanced AI software capabilities. The model’s explicit targeting of “long-running agents” underscores a growing recognition within the AI community that the next frontier of practical AI applications lies in persistent, context-aware systems, rather than isolated, single-turn interactions. This shift demands models that can maintain coherence, recall, and decision-making over extended dialogues and complex tasks without succumbing to the prohibitive costs and latency associated with traditional Transformer architectures at scale.
The architectural choices within Nemotron 3 Ultra are particularly insightful. The adoption of a Mixture-of-Experts (MoE) design, where only a fraction of the total parameters are active per token, represents a sophisticated approach to scaling. This method allows for a massive total parameter count, theoretically enhancing the model’s capacity for knowledge and reasoning, while keeping the active computational footprint manageable. This efficiency is critical for deploying agents in real-world scenarios where continuous operation and rapid response times are non-negotiable. It suggests a future where model scale is decoupled from immediate computational demand, offering a pathway to increasingly powerful yet practical AI.
Furthermore, the hybrid Mamba-Attention architecture addresses a fundamental limitation of pure Transformer models: their quadratic scaling with sequence length. By integrating Mamba layers, which offer sub-quadratic scaling for long sequences, NVIDIA is attempting to combine the best of both worlds – the efficient long-range dependency handling of Mamba with the precise recall capabilities of Attention. This hybrid model represents an important evolutionary step in neural network design for language processing, potentially paving the way for models that can process entire books, extensive codebases, or prolonged human interactions with unprecedented efficiency and understanding. The successful implementation of such a hybrid could set a new standard for how large language models are constructed for demanding agentic tasks.
Competitive Landscape
The release of Nemotron 3 Ultra places NVIDIA in direct competition with established and emerging players in the large language model space, particularly those focusing on agentic AI capabilities. Companies like OpenAI, Google DeepMind, and Anthropic have been actively developing and refining their own flagship models, such as GPT-4, Gemini, and Claude, which are increasingly being leveraged for agent-like applications. While these models have demonstrated impressive general intelligence and multi-modal capabilities, Nemotron 3 Ultra carves out a specific niche by optimizing for the unique challenges of long-running, cost-sensitive agents.
NVIDIA’s strategic advantage lies in its deep integration of hardware and software. The company’s CUDA platform and GPU accelerators are foundational to nearly all major AI developments. By developing a model specifically designed to run efficiently on its own hardware, NVIDIA creates a powerful ecosystem play. This could translate into superior performance and cost-efficiency for Nemotron 3 Ultra when deployed on NVIDIA infrastructure, potentially making it a more attractive option for enterprises already invested in the NVIDIA stack. Competitors, while offering powerful models, might face challenges in matching this level of hardware-software co-optimization for specialized agent workloads.
The hybrid Mamba-Attention architecture also differentiates Nemotron 3 Ultra from many pure Transformer-based models offered by rivals. This architectural innovation could provide a performance edge for extremely long context windows, an area where traditional Transformers can become computationally expensive. As the industry moves towards more complex, autonomous agents requiring vast contextual memory, Nemotron 3 Ultra’s design could position it as a leading solution, compelling competitors to explore similar architectural innovations or risk falling behind in this critical segment of AI development.
Future Implications
In the near-term (3-6 months), Nemotron 3 Ultra is likely to stimulate a wave of experimentation among AI developers and researchers focused on agentic AI. We can expect to see early adopters deploying the model in proof-of-concept projects for complex automation tasks, particularly in customer support, content generation, and specialized data analysis where long-term context is critical. NVIDIA will likely release more detailed benchmarks and developer tools to facilitate adoption and highlight the model’s performance advantages in real-world agent scenarios.
Medium-term (1-2 years) implications include a potential shift in how enterprise AI solutions are designed and implemented. If Nemotron 3 Ultra proves successful in reducing inference costs for long-running agents, it could accelerate the deployment of fully autonomous AI systems in sectors like financial services, healthcare, and advanced manufacturing. This could lead to a proliferation of AI agents that not only understand but actively manage complex workflows, orchestrate multiple tools, and maintain sophisticated reasoning over extended periods, driving significant productivity gains and new service offerings. Other model developers may also begin to incorporate similar hybrid Mamba-Attention or MoE architectures into their own offerings to compete.
Long-term (3-5 years), Nemotron 3 Ultra’s architectural innovations could contribute to the development of truly persistent and adaptive AI. The efficient handling of vast context windows combined with advanced reasoning capabilities might enable AI agents to operate continuously, learning and adapting over months or even years within dynamic environments. This could pave the way for AI systems capable of performing highly complex, open-ended tasks that currently require extensive human oversight, fundamentally changing the nature of work and interaction with digital systems. The focus on cost-efficiency for long runs will be a critical enabler for such pervasive AI.
Actionable Insights
- Developers building AI agents should evaluate Nemotron 3 Ultra for projects requiring extensive context windows and long-running operations to potentially reduce inference costs.
- Enterprises currently deploying AI agents should conduct pilot programs with Nemotron 3 Ultra to assess its performance benefits for multi-turn interactions and complex reasoning tasks.
- Researchers interested in novel AI architectures should study the hybrid Mamba-Attention and Mixture-of-Experts implementation in Nemotron 3 Ultra for insights into future model design.
- AI infrastructure teams should prepare for the potential need to optimize their deployments for hybrid model architectures, moving beyond pure Transformer-centric setups.
- Businesses considering large-scale AI automation should factor in models like Nemotron 3 Ultra, which prioritize long-term cost efficiency and sustained accuracy for agents.
- Stay informed on NVIDIA’s ongoing updates and developer resources for Nemotron 3 Ultra, as further optimizations and use cases are likely to emerge.
What is NVIDIA Nemotron 3 Ultra?
NVIDIA Nemotron 3 Ultra is the largest model in the Nemotron 3 family, a 550 billion total parameter Mixture-of-Experts (MoE) model. It is designed for long-running AI agents that need to plan, use tools, and reason across many interactions.
How does Nemotron 3 Ultra improve efficiency for AI agents?
It uses a Mixture-of-Experts (MoE) design where only 55 billion parameters are active per token, enhancing accuracy per active parameter. Its hybrid Mamba-Attention architecture also handles long sequences with better scaling than pure Transformers, reducing inference costs over time.
What is the significance of its hybrid Mamba-Attention architecture?
The hybrid Mamba-Attention architecture combines Mamba layers for efficient sub-quadratic scaling with long sequences, and Attention layers for precise recall over large contexts. This aims to overcome the computational limitations of pure Transformer models for very long inputs.
How large is Nemotron 3 Ultra’s context window?
Nemotron 3 Ultra was pre-trained on 20 trillion text tokens and its context was subsequently extended to 1 million tokens. This allows it to process and understand very extensive inputs for complex agentic tasks.
Who will benefit most from Nemotron 3 Ultra?
Developers and enterprises building advanced AI agents that require sustained high accuracy, efficient long-term memory, and reduced inference costs for multi-turn interactions will benefit most. This includes applications in customer service, complex automation, and research.
Key Takeaways
- NVIDIA’s Nemotron 3 Ultra is a 550 billion total parameter Mixture-of-Experts model targeting long-running AI agents.
- The model features a hybrid Mamba-Attention architecture for efficient processing of extensive context windows up to 1 million tokens.
- Nemotron 3 Ultra aims to maintain high accuracy while significantly reducing inference costs for complex, multi-turn AI agent tasks.
- Its MoE design activates only 55 billion parameters per token, optimizing for accuracy relative to computational load.
- This release signals a critical advancement in developing more practical, cost-effective, and persistent AI systems for enterprise applications.















