NVIDIA’s AI research team has introduced Dynamo Snapshot, a novel checkpoint/restore system designed to dramatically reduce the cold-start latency for AI inference workloads deployed on Kubernetes. This innovative approach directly addresses the critical issue of idle GPU allocation during the multi-minute startup sequences that currently plague elastic inference deployments. By minimizing the time GPUs spend inactive, Dynamo Snapshot promises to enhance the responsiveness and cost-efficiency of AI services, particularly during sudden surges in user demand. This development is crucial for maintaining Service Level Agreements (SLAs) and ensuring seamless user experiences in production AI environments.
Key Developments
- NVIDIA’s AI research team has unveiled Dynamo Snapshot, a checkpoint/restore solution aimed at accelerating AI inference cold starts on Kubernetes.
- The system targets the significant idle GPU time currently incurred during the several-minute startup process for new inference replicas.
- Dynamo Snapshot specifically addresses the multi-segment cold-start latency, including container image pull, model weight loading, CUDA kernel warm-up, and graph compilation.
- This technology is designed to enable faster scaling of inference workloads, mitigating the risk of SLA violations during unpredictable traffic spikes.
What Happened
NVIDIA’s AI research team has publicly announced Dynamo Snapshot, a new system engineered to tackle the pervasive problem of slow cold starts in AI inference deployments on Kubernetes. This initiative directly confronts the reality that, in production settings, fluctuating demand necessitates the elastic scaling of inference replicas. However, the current process for bringing these new replicas online can extend to several minutes, during which allocated GPUs remain idle, consuming resources without generating tokens or serving requests. This inefficiency represents a significant operational cost and a bottleneck for responsiveness.
The “cold start” phenomenon encompasses a comprehensive sequence of actions a model server must complete before it can process any incoming request. This sequence typically involves pulling the necessary container image, loading substantial model weights into GPU memory, warming up critical CUDA kernels, compiling or capturing CUDA graphs for optimized execution, and finally registering itself with the service discovery layer. Each of these steps contributes to the overall delay, creating a cumulative latency that impacts system performance and user experience.
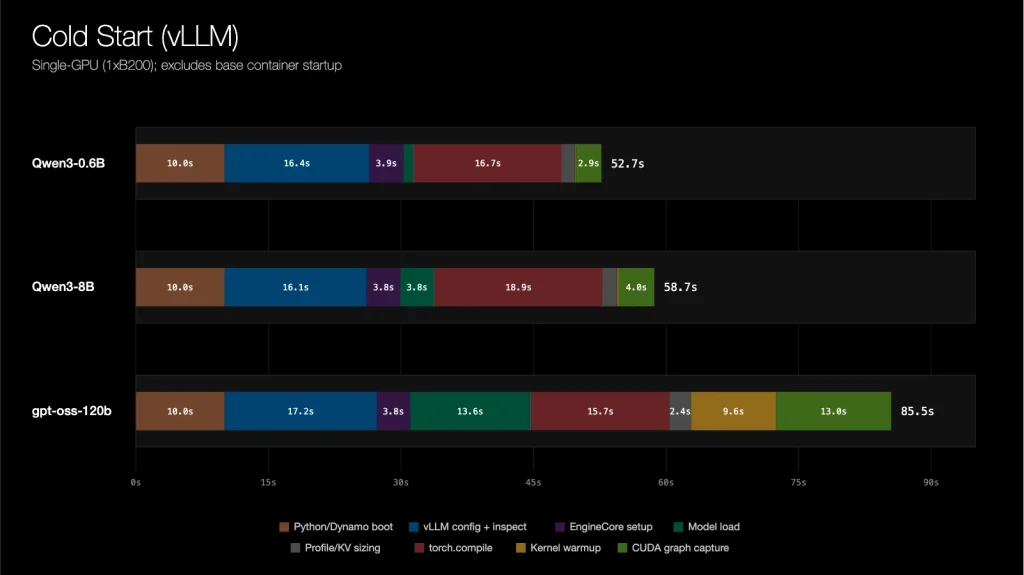
Specifically, for a single-GPU vLLM (version 0.20.0) workload, the cold-start latency is segmented into three distinct phases: the initial container and image pull, the engine initialization which includes weight loading, kernel warm-up, and graph compilation, and the subsequent distributed runtime startup. By introducing Dynamo Snapshot, NVIDIA aims to bypass or significantly shorten these time-consuming segments through a checkpoint/restore mechanism, allowing inference workloads to become operational much more quickly. This strategic development is poised to redefine how AI inference services manage elasticity and resource utilization.
Why It Matters
The introduction of NVIDIA Dynamo Snapshot carries substantial implications for the operational efficiency and reliability of AI inference services. In environments where demand for AI models, especially large language models (LLMs), can surge unpredictably, the ability to scale rapidly is paramount. Traditional cold-start latencies, which can stretch into minutes, mean that during periods of high traffic, systems struggle to provision new inference capacity quickly enough to meet demand. This delay directly increases the risk of Service Level Agreement (SLA) violations, leading to degraded user experiences, lost revenue, and potential reputational damage for businesses relying on these services.
The economic impact of idle GPUs cannot be overstated. When a GPU is allocated but sits dormant waiting for a model to load or kernels to warm up, it represents a direct cost without any corresponding value generation. Dynamo Snapshot’s ability to drastically reduce this idle time translates directly into more efficient resource utilization and lower operational expenditures for cloud-based AI deployments. Furthermore, by enabling near-instantaneous scaling, organizations can be more aggressive in their auto-scaling policies, ensuring optimal resource allocation without over-provisioning for peak loads that may not materialize. This shift from reactive, slow scaling to proactive, rapid response is a fundamental change in how AI infrastructure can be managed and optimized.
The competitive landscape for AI infrastructure providers is intense, with every millisecond of latency and every dollar of operational cost under scrutiny. Solutions that offer a tangible advantage in performance and efficiency can significantly differentiate offerings. For enterprises building and deploying AI-powered applications, Dynamo Snapshot offers a critical tool to enhance the resilience and responsiveness of their services, directly impacting their ability to deliver consistent performance to end-users and maintain competitive advantage in a fast-moving market.
Industry Impact
NVIDIA Dynamo Snapshot is set to significantly influence various sectors heavily reliant on real-time or near real-time AI inference. Industries such as financial services, which use AI for fraud detection and algorithmic trading, stand to benefit from the ability to instantly scale inference capacity to handle sudden data spikes or market events. Similarly, e-commerce platforms, which leverage AI for personalized recommendations and dynamic pricing, can ensure uninterrupted, high-quality user experiences even during peak shopping seasons, preventing lost sales due to slow responses.
The burgeoning field of generative AI, including applications built on large language models (LLMs) for content creation, customer service chatbots, and code generation, will experience a profound impact. These applications often face highly variable usage patterns, from periods of low activity to viral surges. Dynamo Snapshot allows providers of these services to scale their GPU-backed inference infrastructure with unprecedented speed, ensuring that users receive immediate responses without perceptible delays, which is critical for maintaining engagement and satisfaction. This capability directly enhances the viability of deploying sophisticated AI models in production environments where responsiveness is a key performance indicator.
Beyond specific industries, the broader cloud computing ecosystem and AI infrastructure providers will feel the ripple effects. Companies offering managed Kubernetes services or specialized AI platforms will find Dynamo Snapshot an attractive feature to integrate, enhancing their value proposition to customers. It enables them to promise higher uptime and better performance guarantees for AI workloads. This innovation could also spur further research and development into similar checkpoint/restore mechanisms for other computationally intensive cloud-native applications, extending the benefits of faster startup times beyond just AI inference.
Analysis
The persistent challenge of cold-start latency in AI inference on Kubernetes has been a significant hurdle for organizations striving for both efficiency and elasticity in their production deployments. The multi-minute delays described are not merely an inconvenience; they represent a fundamental architectural impedance mismatch between the dynamic nature of cloud-native orchestration and the monolithic, resource-intensive requirements of loading complex AI models onto specialized hardware. NVIDIA’s Dynamo Snapshot directly confronts this impedance by introducing a mechanism that effectively “pauses” and “resumes” the state of an inference workload, sidestepping the repetitive and time-consuming initialization steps.
This approach moves beyond mere optimization of individual startup components, such as faster image pulls or more efficient kernel warm-ups, by offering a systemic solution. The ability to checkpoint the state after model weights are loaded, CUDA kernels are warmed, and graphs are compiled means that subsequent instances can bypass these initial resource-intensive stages. This is particularly salient for large models where weight loading alone can consume significant time and memory bandwidth. By focusing on the entire sequence from container pull to service registration, Dynamo Snapshot provides a comprehensive answer to a problem that has previously required fragmented solutions.
The strategic importance of this development for NVIDIA extends beyond simply improving performance; it reinforces their position as a critical enabler of AI infrastructure. As the primary provider of GPUs essential for AI inference, any innovation that makes their hardware more efficient and easier to deploy at scale directly benefits their core business. By offering tools like Dynamo Snapshot, NVIDIA helps enterprises overcome one of the major operational friction points in AI adoption, thereby encouraging broader and more ambitious deployments of AI models on their platforms. This creates a stronger ecosystem around NVIDIA’s hardware and software stack, solidifying its market leadership in AI compute.
Head-to-Head Comparison
| Feature | NVIDIA Dynamo Snapshot | Traditional Kubernetes Cold Start |
|---|---|---|
| Pricing | No direct cost, integrated with NVIDIA AI ecosystem | Indirect costs from idle GPU time and potential SLA penalties |
| Performance | Significantly reduced cold-start latency (minutes to seconds) | Several minutes for full model server initialization |
| Best For | Elastic AI inference workloads, LLM deployments, high-demand services | Workloads with infrequent scaling or less stringent latency requirements |
| Key Strength | Checkpoint/restore of entire inference state, bypassing complex initialization | Standard, widely understood Kubernetes deployment patterns |
| Main Weakness | Requires specific integration with NVIDIA’s ecosystem | High latency during scaling events, inefficient GPU utilization |
Competitive Landscape
While NVIDIA’s Dynamo Snapshot offers a distinct advantage in mitigating AI inference cold starts, the broader competitive landscape for optimizing AI deployments on Kubernetes is diverse. Cloud providers like AWS, Google Cloud, and Microsoft Azure continually invest in their own managed Kubernetes services and AI inference platforms, offering features such as optimized container images, custom runtimes, and specialized hardware configurations to accelerate AI workloads. These platforms often provide proprietary solutions for faster image pulling or more efficient resource allocation, though typically not a full checkpoint/restore mechanism for the entire inference stack.
Open-source projects and other vendors also contribute to this space. Projects like KServe and Kubeflow aim to simplify the deployment and scaling of machine learning models on Kubernetes, often integrating with various model servers and inferencing engines. While these projects provide orchestration and management capabilities, they generally rely on underlying infrastructure optimizations rather than a deep, stateful checkpointing approach like Dynamo Snapshot. The focus for these competitors tends to be on streamlining the deployment pipeline and abstracting away complexity, rather than fundamentally altering the startup sequence itself.
The unique value proposition of Dynamo Snapshot lies in its ability to address the “engine initialization” phase directly, which involves loading model weights, warming CUDA kernels, and compiling graphs – steps that are deeply tied to NVIDIA’s GPU architecture and software stack. This gives NVIDIA a proprietary edge in optimizing performance at a foundational level that generic Kubernetes or cloud-native solutions may not easily replicate without significant collaboration or direct integration with NVIDIA’s technologies. Competitors will likely explore similar stateful snapshotting techniques or seek deeper integration with NVIDIA’s offerings to match this capability.
Future Implications
In the near-term (3-6 months), we anticipate a rapid adoption curve for Dynamo Snapshot within organizations heavily invested in NVIDIA’s AI ecosystem, particularly those struggling with the cost and performance implications of elastic inference on Kubernetes. Expect to see early case studies and benchmarks demonstrating significant reductions in cold-start times, driving increased interest from cloud service providers and large enterprises. This will likely lead to more robust integration guides and best practices emerging from NVIDIA and its partners.
Medium-term (1-2 years) projections suggest that the success of Dynamo Snapshot will spur further innovation in stateful application management within cloud-native environments. We could see the emergence of similar checkpoint/restore paradigms for other computationally intensive workloads beyond AI inference, potentially extending to complex data processing pipelines or real-time analytics engines. This could also lead to a standardization push for checkpointing APIs within Kubernetes, allowing for broader interoperability and vendor-agnostic solutions. Furthermore, the efficiency gains will enable more ambitious and complex AI models to be deployed elastically, pushing the boundaries of real-time AI applications.
Long-term (3-5 years) implications include a fundamental shift in how AI infrastructure is designed and operated. The ability to instantly scale AI models will make “always-on, infinitely scalable” AI services a practical reality, rather than an aspirational goal. This could democratize access to sophisticated AI, allowing smaller organizations to deploy powerful models without needing to over-provision expensive GPU resources. We might also see the development of “AI-as-a-Utility” models, where compute resources for inference are metered with extreme precision, only charging for active processing rather than idle allocation, driven by the efficiencies enabled by technologies like Dynamo Snapshot.
Actionable Insights
- Evaluate your current AI inference cold-start latencies and identify the specific bottlenecks in your Kubernetes deployments.
- Investigate integrating NVIDIA Dynamo Snapshot into your existing AI inference pipelines, especially for critical, latency-sensitive applications.
- Prioritize container image optimization and efficient model loading strategies to complement the benefits of checkpoint/restore systems.
- Collaborate with your cloud provider or infrastructure team to ensure your Kubernetes clusters are configured to leverage fast storage and network access for snapshot operations.
- Monitor your GPU utilization metrics closely before and after implementing Dynamo Snapshot to quantify the efficiency gains and cost savings.
- Stay informed about future updates and integrations of Dynamo Snapshot with other NVIDIA AI software and popular MLOps platforms.
What is NVIDIA Dynamo Snapshot?
NVIDIA Dynamo Snapshot is a checkpoint/restore system developed by NVIDIA’s AI research team to significantly reduce the cold-start latency for AI inference workloads deployed on Kubernetes. It allows the state of an inference workload to be saved and quickly restored, bypassing lengthy initialization processes.
Why is AI inference cold-start latency a problem?
Cold-start latency in AI inference on Kubernetes can take several minutes, during which allocated GPUs remain idle and unproductive. This delay prevents rapid scaling during traffic spikes, increases the risk of SLA violations, and leads to inefficient resource utilization and higher operational costs.
What components contribute to AI inference cold-start time?
The cold-start process for AI inference includes pulling the container image, loading model weights into GPU memory, warming up CUDA kernels, compiling or capturing CUDA graphs, and registering with the service discovery layer. Each of these steps adds to the overall delay.
How does Dynamo Snapshot reduce cold-start times?
Dynamo Snapshot reduces cold-start times by using a checkpoint/restore approach. It captures the state of an inference workload after the initial, time-consuming setup phases, allowing new replicas to start from this pre-initialized state much faster than performing a full cold start.
What are the main benefits of using Dynamo Snapshot?
The main benefits include faster scaling of AI inference workloads, improved responsiveness to traffic spikes, reduced GPU idle time leading to cost savings, and better adherence to Service Level Agreements (SLAs) for AI-powered applications.
Key Takeaways
- NVIDIA Dynamo Snapshot addresses AI inference cold-start latency on Kubernetes through a checkpoint/restore system.
- Cold starts currently involve multi-minute delays for tasks like image pull, model loading, and kernel warm-up, leading to idle GPUs.
- This new system aims to significantly reduce the time it takes for AI inference replicas to become operational.
- Faster startup times will enable more elastic scaling, better SLA adherence, and improved resource efficiency for AI deployments.
- Dynamo Snapshot enhances NVIDIA’s ecosystem by making GPU-accelerated AI inference more practical and cost-effective in production.