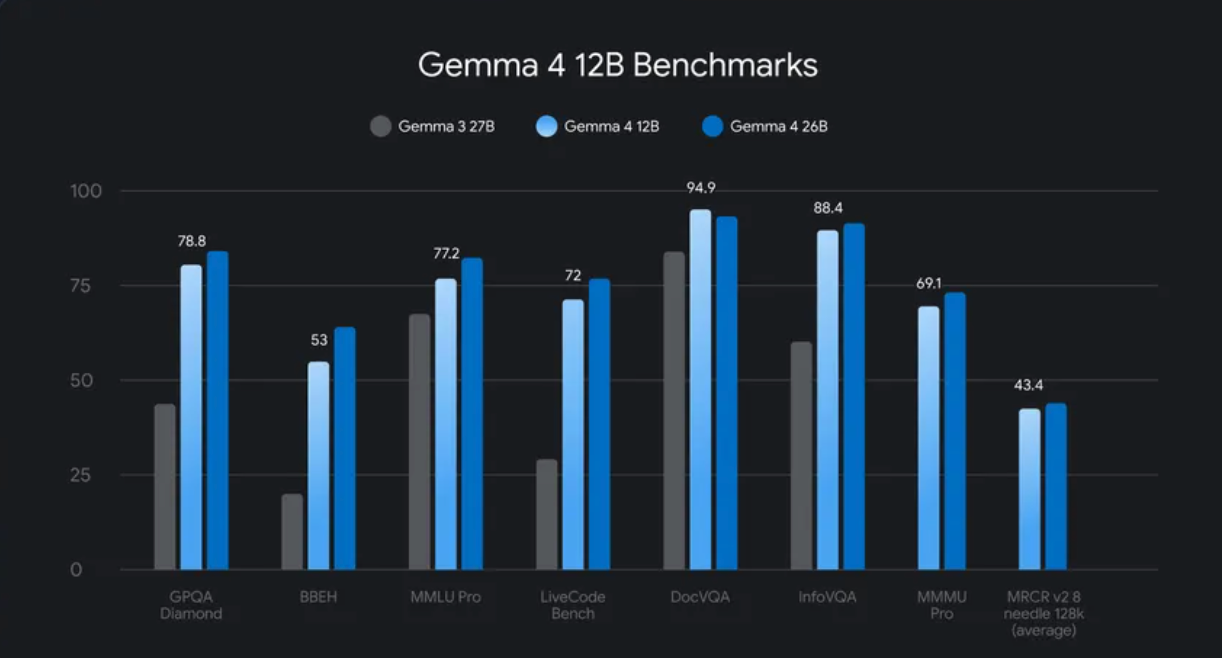
Google DeepMind just released Gemma 4 12B, a 12-billion-parameter multimodal model that operates without traditional encoders for vision and audio input. This novel architecture allows visual and auditory data to flow directly into the large language model’s core, enabling complex agentic workflows on consumer-grade hardware. Specifically, the model is designed to run efficiently on laptops equipped with 16 GB of RAM, including Apple Silicon Macs, making advanced AI capabilities more accessible than ever. This development signifies a critical step towards democratizing sophisticated AI by lowering the hardware barrier for advanced multimodal applications.
Key Developments
- Gemma 4 12B is a 12-billion-parameter dense multimodal model released by Google DeepMind.
- The model features an encoder-free architecture, processing text, image, video, and native audio directly through its decoder-only transformer.
- It is designed to operate on consumer laptops with
16 GBVRAM or unified memory
, including Apple Silicon Macs.
- Gemma 4 12B is distributed under the Apache 2.0 license, facilitating broad adoption and development.
- This release introduces native audio capabilities to a mid-sized Gemma model for the first time, bridging the gap between edge-friendly and larger Mixture of Experts variants.
What Happened
Google DeepMind officially unveiled Gemma 4 12B, a significant addition to its family of open models, distinguishing itself through an innovative architectural approach. Unlike many existing multimodal models that rely on separate encoders to pre-process vision and audio data, Gemma 4 12B integrates these modalities directly into its decoder-only transformer backbone. This unified design simplifies the processing pipeline and reduces computational overhead.
The model functions as a decoder-only transformer, mirroring the structural principles of the larger Gemma 4 31B Dense model. This consistency in design suggests a scalable and efficient foundation across different parameter counts within the Gemma family. Its capacity to handle text, images, video, and, notably, native audio input marks a notable expansion of capabilities for a model of its size, particularly bringing audio processing to the mid-tier Gemma range for the first time.
The release also underscores Google DeepMind’s commitment to broader accessibility for advanced AI tools. By optimizing Gemma 4 12B to function on hardware as common as a consumer laptop with 16 GB of VRAM or unified memory, the company is directly addressing the resource constraints that often limit AI development and deployment. The Apache 2.0 license further reinforces this accessibility, allowing developers and researchers to utilize and build upon the model without restrictive commercial terms.
Why It Matters
The introduction of Gemma 4 12B holds profound implications for the AI industry, primarily by democratizing access to powerful multimodal AI capabilities. Historically, running advanced AI models required significant computational resources, often necessitating cloud infrastructure or high-end specialized hardware. This new model dramatically lowers that barrier, making sophisticated AI workflows feasible on everyday consumer devices. This shift could accelerate innovation by putting development tools directly into the hands of a much wider audience, from independent developers to small businesses.
From a competitive standpoint, Gemma 4 12B challenges the notion that advanced multimodal AI is exclusively the domain of massive, resource-intensive models. Its ability to perform agentic workflows on a standard laptop suggests a future where AI agents can operate more autonomously and locally, reducing latency and reliance on continuous internet connectivity. This could open new avenues for offline AI applications, enhanced privacy, and personalized AI experiences directly on user devices. The Apache 2.0 license also positions it as a strong contender in the open-source AI landscape, potentially fostering a vibrant ecosystem of community-driven enhancements and applications.
The model’s encoder-free architecture is a technical breakthrough with significant practical benefits. By eliminating separate encoders, Gemma 4 12B achieves greater efficiency and potentially a more coherent understanding across modalities, as all data types are processed within a unified framework. This streamlined approach could lead to more robust and versatile multimodal applications, from intelligent assistants that understand spoken commands and visual cues simultaneously, to creative tools that generate content based on diverse inputs. The immediate impact is a wider array of developers experimenting with and deploying complex AI solutions, accelerating the pace of real-world AI integration.
Industry Impact
The release of Gemma 4 12B is poised to send ripples across several sectors of the AI and technology industry. For hardware manufacturers, particularly those in the consumer GPU and personal computing space, it validates the increasing demand for local AI processing power. Companies like Apple, with its unified memory architecture, and NVIDIA, with its consumer-grade GPUs, will see increased utility and market validation for their products as more powerful models become deployable on their platforms. This could spur further optimization in consumer hardware design specifically for on-device AI.
Software developers and startups, especially those focused on edge computing and mobile AI, will find a powerful new tool in Gemma 4 12B. The model’s ability to run complex multimodal tasks on a laptop removes a significant barrier to entry for developing applications that require real-time processing of diverse data streams without relying on cloud infrastructure. This could lead to a proliferation of new applications in areas such as intelligent personal assistants, localized content creation tools, interactive educational software, and enhanced accessibility solutions that operate directly on user devices, offering improved privacy and responsiveness.
The open-source nature of Gemma 4 12B, under the Apache 2.0 license, will also energize the broader AI research community. Researchers can now experiment with an advanced multimodal architecture that is both efficient and accessible, fostering collaborative development and faster iteration on new AI techniques. This could lead to breakthroughs in areas like multimodal reasoning, embodied AI, and more nuanced human-computer interaction, as the community explores the full potential of an encoder-free, natively multimodal model. The competitive landscape for open-source foundation models will intensify, pushing other major players to respond with similarly accessible and capable offerings.
Head-to-Head Comparison
| Feature | Gemma 4 12B | Other Mid-Sized Multimodal Models (General) |
|---|---|---|
| Pricing | Free (Apache 2.0 License) | Varies (often proprietary, or open-source with differing licenses) |
| Performance | Designed for agentic workflows on 16 GB RAM laptops; encoder-free architecture. | Performance varies widely; often requires more VRAM or cloud resources for similar multimodal tasks. |
| Best For | On-device multimodal AI applications, local agentic workflows, open-source development, researchers with consumer hardware. | Cloud-based applications, specific enterprise integrations, developers with access to higher-end infrastructure. |
| Key Strength | Encoder-free unified architecture, native audio processing, low hardware requirement for advanced multimodal tasks, open-source. | May have larger parameter counts, specialized fine-tuning for specific tasks, broader commercial support. |
| Main Weakness | Parameter count of 12B might limit ultimate complexity compared to much larger models. | Often higher hardware requirements, potential licensing restrictions, may lack native audio or unified multimodal architecture. |
Analysis
Google DeepMind’s strategic release of Gemma 4 12B represents a calculated move to redefine the accessibility and deployment paradigm for multimodal AI. By stripping away traditional encoders, the model not only achieves a leaner architecture but also potentially fosters a more integrated understanding across diverse data types. This encoder-free approach suggests a future where AI models inherently perceive the world through a unified lens, rather than stitching together outputs from disparate processing units. The implications for real-time interaction and context awareness are substantial, as the model can theoretically process and relate visual, auditory, and textual information with greater coherence and speed.
The emphasis on running on
is not merely a technical specification; it is a declaration of intent to push advanced AI beyond the data center. This focus on edge computing capabilities suggests that Google DeepMind envisions a future where AI agents are highly personalized, context-aware, and capable of operating directly on user devices with enhanced privacy and reduced latency. The Apache 2.0 license further amplifies this vision, creating an environment where a broad community can experiment, build, and deploy these advanced capabilities without the prohibitive costs or restrictive terms often associated with proprietary models.
This development could also be interpreted as a strategic response to the growing demand for more efficient and deployable AI. As the industry grapples with the environmental and economic costs of increasingly large models, Gemma 4 12B offers a compelling alternative that prioritizes efficiency without sacrificing multimodal sophistication. The model’s position as a bridge between edge-friendly variants and larger Mixture of Experts models within the Gemma family highlights a deliberate strategy to offer a spectrum of accessible, high-performance AI tools, catering to diverse development needs and hardware constraints. This positions Google DeepMind to capture a significant share of the burgeoning market for on-device and open-source AI applications.
✓ Pros
- Encoder-free architecture for unified multimodal processing.
- Native audio input, a first for mid-sized Gemma models.
- Low hardware requirement (16 GB RAM) enables local execution.
- Apache 2.0 license fosters open development and broad adoption.
- Supports agentic workflows on consumer devices.
✗ Cons
- 12B parameters may be less capable than much larger, cloud-based models for certain complex tasks.
- Performance on diverse hardware configurations will require real-world validation.
- New architecture may require adaptation for developers accustomed to encoder-based systems.
Competitive Landscape
The release of Google DeepMind’s Gemma 4 12B intensifies the competition within the rapidly expanding field of open-source multimodal AI models. While established players like OpenAI and Anthropic primarily offer proprietary, cloud-based solutions, the open-source sector, led by Meta with Llama and other community-driven projects, is gaining significant traction. Gemma 4 12B directly competes with models aiming for broader accessibility and on-device deployment, such as smaller Llama variants or specialized edge-optimized models from other research groups. Its unique encoder-free architecture and native audio capabilities set it apart, offering a distinct advantage in efficiency and integrated multimodal understanding compared to models that might rely on separate processing stages for different data types. This move could pressure competitors to either open-source more capable models or develop similarly efficient architectures to remain competitive in the accessible AI space.
Future Implications
Near-term (3–6 months): We will likely see a rapid proliferation of new applications built on Gemma 4 12B, particularly in personal computing and mobile spaces, as developers leverage its on-device capabilities for agentic workflows and multimodal interactions. Expect increased community engagement and fine-tuning efforts under the Apache 2.0 license.
Medium-term (1–2 years): The success of Gemma 4 12B could drive a broader industry shift towards encoder-free or highly integrated multimodal architectures, influencing the design of future foundation models. Hardware manufacturers may also accelerate the development of consumer-grade GPUs and unified memory systems optimized for these types of efficient, local AI models.
Long-term (3–5 years): Gemma 4 12B and its successors could fundamentally alter how we interact with AI, enabling highly personalized, always-on AI agents that operate entirely on local devices, enhancing privacy and reducing reliance on cloud infrastructure. This could lead to a significant decentralization of AI processing power, fostering innovation in areas like augmented reality and ambient computing.
Actionable Insights
- Developers should immediately explore Gemma 4 12B to understand its encoder-free architecture and native audio processing capabilities for potential integration into new or existing projects.
- Hardware enthusiasts and researchers with 16 GB RAM laptops or Apple Silicon Macs can begin experimenting with the model locally to assess its performance and potential for on-device AI applications.
- Businesses considering AI solutions for edge devices or applications requiring multimodal understanding should evaluate Gemma 4 12B as a cost-effective and efficient alternative to cloud-based or resource-intensive models.
- AI product managers should analyze the implications of an accessible, on-device multimodal model for their product roadmaps, particularly concerning privacy, real-time processing, and offline functionality.
- Individuals interested in open-source AI contributions should monitor the Gemma 4 12B community for opportunities to contribute to its development, fine-tuning, and application ecosystem.
What is Google DeepMind’s Gemma 4 12B?
Gemma 4 12B is a 12-billion-parameter multimodal AI model released by Google DeepMind. It is notable for its encoder-free architecture, allowing it to natively process text, images, video, and audio directly within its decoder-only transformer.
What makes Gemma 4 12B’s architecture unique?
Its unique encoder-free design means it does not use separate encoders for vision and audio. Instead, these modalities flow directly into the LLM backbone, simplifying processing and enabling more unified understanding across data types.
What hardware is required to run Gemma 4 12B?
Gemma 4 12B is optimized to run efficiently on consumer laptops with 16 GB of VRAM or unified memory. This includes common consumer GPU laptops and Apple Silicon Macs, making advanced AI more accessible.
What kind of license does Gemma 4 12B use?
The model is released under the Apache 2.0 license. This open-source license allows for broad use, modification, and distribution, fostering community development and commercial applications.
What are the key benefits of Gemma 4 12B?
Key benefits include its ability to run complex multimodal agentic workflows on consumer hardware, native audio processing for the first time in a mid-sized Gemma model, and its open-source nature, which promotes innovation and widespread adoption.
Key Takeaways
- Gemma 4 12B is a 12-billion-parameter multimodal model from Google DeepMind, featuring an encoder-free architecture.
- The model natively processes text, image, video, and audio directly through its decoder-only transformer.
- It runs efficiently on consumer laptops with 16 GB of VRAM or unified memory, including Apple Silicon Macs.
- Gemma 4 12B is distributed under the permissive Apache 2.0 open-source license.
- This release significantly lowers the hardware barrier for advanced multimodal AI, enabling broader local deployment and development.
















