NVIDIA has unveiled X-Token, a novel knowledge distillation method that significantly elevates the performance of smaller language models, achieving an average improvement of
over existing state-of-the-art techniques like GOLD. This advancement directly addresses a long-standing challenge in AI: enabling effective knowledge transfer between models with incompatible tokenizers, which previously hindered the adoption of stronger teacher models for distillation. By circumventing the need for shared vocabularies, X-Token opens new avenues for leveraging diverse, high-performing teacher models to enhance smaller student architectures. This innovation is critical for developers seeking to deploy efficient, powerful AI models in resource-constrained environments without compromising on performance.
Key Developments
- NVIDIA introduced X-Token, a new logit-distribution-based method for cross-tokenizer knowledge distillation (KD).
- X-Token operates as a direct replacement for standard KD loss, requiring no additional trainable components or architectural modifications.
- The method allows smaller student models, such as Llama-3.2-1B, to learn from larger teacher models with different tokenizers, a capability previously limited.
- X-Token demonstrated an average performance gain of +3.82 points on Llama-3.2-1B compared to the GOLD method, a leading prior approach.
- This innovation facilitates multi-teacher distillation across various tokenizer families, expanding the possibilities for model improvement.
What Happened
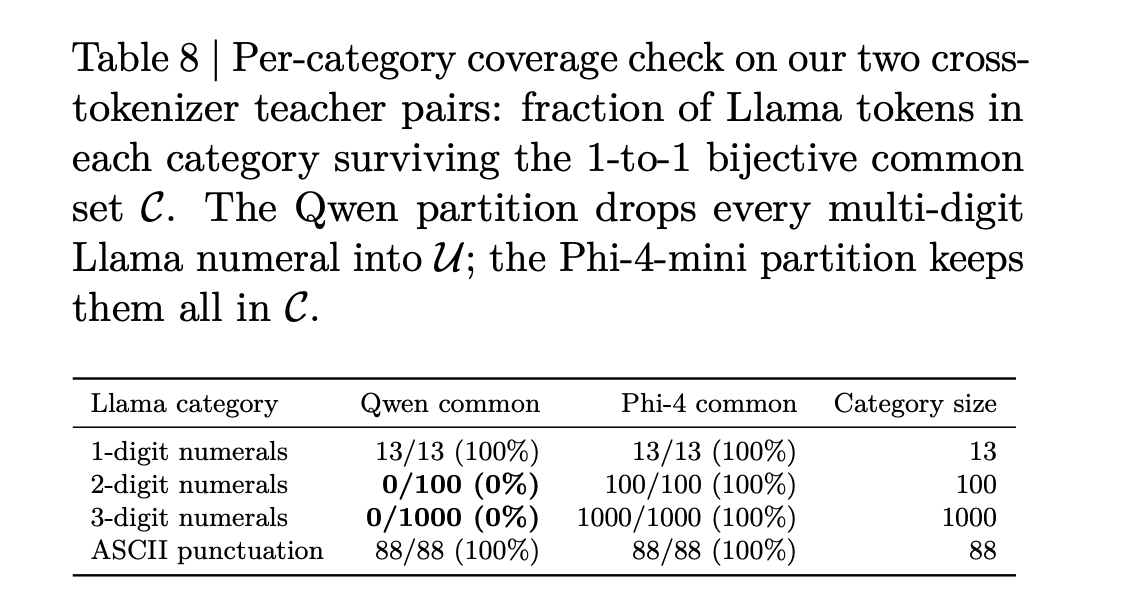
NVIDIA researchers recently introduced X-Token, an innovative approach designed to overcome a significant hurdle in knowledge distillation: the incompatibility of tokenizers between teacher and student models. Knowledge distillation (KD) typically involves transferring “dark knowledge” from a large, powerful teacher model to a smaller student model by having the student learn from the teacher’s full output probability distribution over tokens. This process, often quantified by per-position Kullback–Leibler (KL) divergence, has traditionally mandated that both models share an identical tokenizer to ensure token positions correspond across vocabularies.
The absence of a shared tokenizer has meant that practitioners committed to a specific student model, such as Llama-3.2-1B, could not benefit from the superior performance of teacher models like Phi-4-mini or Qwen3-4B if their tokenizers differed. X-Token directly addresses this limitation by offering a logit-distribution-based method that enables cross-tokenizer KD. It functions as a drop-in replacement for the conventional KD loss, meaning it requires no auxiliary trainable components, no modifications to the student model’s architecture, and no changes to the training pipeline beyond swapping out the loss function. This simplicity in integration is a key aspect of its design, aiming for broad applicability and ease of use for AI developers.
Why It Matters
The introduction of X-Token carries substantial implications for the field of artificial intelligence, particularly for the deployment of efficient language models. Historically, the requirement for identical tokenizers in knowledge distillation has created a bottleneck, preventing smaller models from inheriting the full spectrum of knowledge from the most powerful available teachers. This restriction forced developers to choose between using a sub-optimal teacher with a compatible tokenizer or foregoing distillation benefits entirely.
X-Token’s ability to bridge this tokenizer gap means that a Llama-3.2-1B student model can now learn from a Phi-4-mini or Qwen3-4B teacher, regardless of their tokenizer differences. This directly translates into smaller, more efficient models that perform at significantly higher levels. For businesses, this means the potential to deploy AI solutions with reduced computational overhead, faster inference times, and lower energy consumption, all while delivering enhanced accuracy and capability. The competitive dynamics shift as companies can now more effectively optimize their model portfolios, balancing size and performance without the previous constraints.
This performance uplift, demonstrated by the +3.82 average point gain on Llama-3.2-1B, is not merely an academic achievement; it represents a tangible improvement in practical model utility. It empowers developers to build more capable AI applications, from advanced chatbots to sophisticated content generation systems, that are both high-performing and economically viable for deployment.
Industry Impact
The impact of NVIDIA’s X-Token extends across numerous sectors, fundamentally altering how organizations approach the development and deployment of AI models. Industries heavily reliant on efficient natural language processing, such as customer service, financial analysis, healthcare, and content creation, stand to benefit immensely. For instance, a fintech company developing a lightweight model for real-time fraud detection can now distill knowledge from a state-of-the-art, larger financial language model, even if their tokenization schemes differ. This enables the deployment of highly accurate, specialized models directly onto edge devices or within resource-constrained cloud environments.
In healthcare, smaller, specialized models trained with X-Token could enhance diagnostic tools or patient interaction systems, running efficiently on hospital infrastructure without requiring massive computational resources. Content generation platforms can leverage this technology to create more nuanced and contextually aware outputs from smaller models, reducing the cost of generating high-quality text. The ability to perform multi-teacher distillation across disparate tokenizer families further amplifies this effect, allowing student models to synthesize “dark knowledge” from a diverse set of expert teachers, leading to more robust and versatile AI agents. This democratizes access to high-performance AI, moving it beyond organizations with vast computational budgets.
Expert Analysis
The challenge of cross-tokenizer knowledge distillation has been a persistent one, often forcing a trade-off between model performance and architectural flexibility. NVIDIA’s X-Token represents a significant methodological leap, moving beyond prior attempts that either discarded token identity entirely, like Universal Logit Distillation (ULD), or introduced complex auxiliary components. Its elegance lies in its simplicity as a drop-in replacement, signaling a mature understanding of practical deployment constraints.
The core innovation appears to be in its projection-guided approach to aligning logit distributions, effectively bypassing the need for direct vocabulary correspondence. This is not just a marginal improvement; the
on top of existing methods like GOLD is substantial in a field where fractional percentage gains are often celebrated. This level of performance enhancement, coupled with the minimal integration effort, positions X-Token as a potentially ubiquitous component in future knowledge distillation pipelines. It suggests a future where model builders are less constrained by the idiosyncrasies of tokenization and more focused on the semantic knowledge transfer itself.
This development underscores a broader trend in AI research: the increasing focus on practical challenges that hinder real-world deployment. While large model training continues to push boundaries, innovations like X-Token ensure that the benefits of these advancements can be effectively transferred to models suitable for production environments. It democratizes access to state-of-the-art model capabilities, making high-performance AI more accessible to a wider array of applications and organizations.
Competitive Landscape
The introduction of NVIDIA’s X-Token intensifies the competitive landscape within the AI model optimization and deployment sector. While companies like Google’s DeepMind and OpenAI continue to push the boundaries of large model pre-training, NVIDIA is strategically focusing on the critical bridge between these massive models and their practical, efficient deployment. Prior to X-Token, methods like Universal Logit Distillation (ULD) and GOLD represented the state-of-the-art for cross-tokenizer knowledge distillation, each with its own trade-offs regarding complexity and performance. ULD, for instance, simplified the problem by sorting distributions and minimizing L1 distance, effectively discarding token identity. GOLD added more sophistication by incorporating span-based alignment.
X-Token now sets a new benchmark, outperforming GOLD by a significant margin of +3.82 average points on Llama-3.2-1B, without adding the complexity of auxiliary components. This places NVIDIA in a strong position to influence the tooling and methodologies used by developers building efficient AI applications. Competitors offering model compression or optimization services will need to either integrate similar capabilities or risk being outmatched in terms of student model performance and flexibility. This innovation could also spur other research institutions and AI companies to explore alternative projection-guided or logit-distribution alignment techniques to catch up, further accelerating advancements in efficient AI deployment.
Future Implications
The immediate future (3-6 months) will likely see a rapid adoption of X-Token by developers and researchers working on knowledge distillation tasks. Its ease of integration and significant performance gains will make it an attractive option for improving existing student models. We can expect to see an increase in open-source projects and academic papers leveraging X-Token for various language model compression efforts.
In the medium term (1-2 years), X-Token’s influence could lead to a proliferation of highly specialized, efficient language models tailored for specific industry applications. The ability to combine knowledge from multiple, diverse teacher models will enable the creation of “super-students” that exhibit capabilities beyond what a single teacher could impart. This could significantly lower the barrier to entry for deploying advanced AI in sectors currently limited by computational resources or model size.
Longer term (3-5 years), X-Token and similar advancements could fundamentally reshape how AI models are designed and maintained. The focus might shift from training monolithic, general-purpose models to developing modular systems where smaller, highly optimized student models are continuously distilled from an evolving ensemble of powerful, specialized teachers. This could lead to more adaptive, resource-efficient, and easily updateable AI systems, blurring the lines between model training and ongoing knowledge transfer.
Actionable Insights
- Evaluate Current Distillation Pipelines: Assess whether your existing knowledge distillation processes are constrained by tokenizer compatibility and consider X-Token as a potential solution.
- Experiment with Cross-Tokenizer Teachers: Explore distilling knowledge from previously incompatible, higher-performing teacher models to enhance your student models’ capabilities.
- Benchmark X-Token Performance: Implement X-Token in your specific use cases and conduct thorough benchmarking against existing KD methods to quantify performance improvements.
- Allocate Resources for Model Optimization: Prioritize investments in model optimization techniques like cross-tokenizer KD to improve efficiency and reduce inference costs.
- Stay Informed on NVIDIA’s AI Tools: Monitor NVIDIA’s ongoing research and development in AI optimization, as X-Token is likely a precursor to further innovations in this area.
- Consider Multi-Teacher Distillation: Investigate the potential of using multiple teacher models from different tokenizer families to create more robust and knowledgeable student models.
What problem does NVIDIA’s X-Token solve in AI?
X-Token addresses the challenge of knowledge distillation between AI models that use incompatible tokenizers. Previously, a student model could only learn from a teacher model if they shared the same tokenizer, limiting the choice of powerful teachers.
How does X-Token improve upon existing knowledge distillation methods?
X-Token outperforms prior cross-tokenizer KD methods like GOLD by +3.82 average points on Llama-3.2-1B, without requiring auxiliary trainable components or architectural changes. It achieves this by aligning logit distributions rather than relying on token identity.
Can X-Token be easily integrated into existing AI training workflows?
Yes, X-Token is designed as a drop-in replacement for the standard knowledge distillation loss function. This means it requires no modifications to the student model’s architecture or the overall training pipeline, making integration straightforward.
What are the benefits of using X-Token for smaller language models?
X-Token allows smaller language models to achieve significantly higher performance by learning from stronger teacher models, regardless of tokenizer differences. This leads to more efficient, capable models suitable for resource-constrained deployments.
Does X-Token support multi-teacher distillation?
Yes, X-Token facilitates multi-teacher distillation across different tokenizer families. This enables student models to learn from a diverse set of expert teachers, potentially leading to more robust and versatile AI capabilities.
Key Takeaways
- NVIDIA’s X-Token significantly improves cross-tokenizer knowledge distillation, enabling student models to learn from teachers with different vocabularies.
- X-Token delivers an average performance increase of +3.82 points on Llama-3.2-1B over the GOLD method, setting a new benchmark for efficiency.
- The method integrates seamlessly as a drop-in replacement for standard KD loss, requiring no architectural changes or auxiliary components.
- This innovation democratizes access to high-performance AI, allowing smaller models to achieve advanced capabilities for resource-constrained deployments.
- X-Token opens new possibilities for multi-teacher distillation, enhancing the robustness and versatility of student models.