Miso Labs has introduced MisoTTS, an 8-billion-parameter text-to-speech model with open weights, designed to generate expressive speech from both textual input and accompanying audio context. This release marks a notable advancement in the accessibility of high-fidelity voice synthesis, offering developers and researchers a powerful new tool. The model’s architecture incorporates residual vector quantization (RVQ) to expand its sonic capabilities without proportionally increasing parameter count, addressing a common challenge in large-scale speech models. Its claimed inference latency of 110ms significantly undercuts established industry benchmarks, positioning MisoTTS as a potentially disruptive force in real-time audio generation.
Key Developments
- Miso Labs has released MisoTTS, an 8-billion-parameter text-to-speech model with open weights.
- MisoTTS generates expressive speech by conditioning on both text and optional prior audio context.
- The model utilizes residual vector quantization (RVQ) to enhance its sonic range while maintaining a fixed parameter count.
- MisoTTS boasts a claimed inference latency of 110ms, which is significantly faster than competitors like ElevenLabs (700ms) and Sesame (300ms).
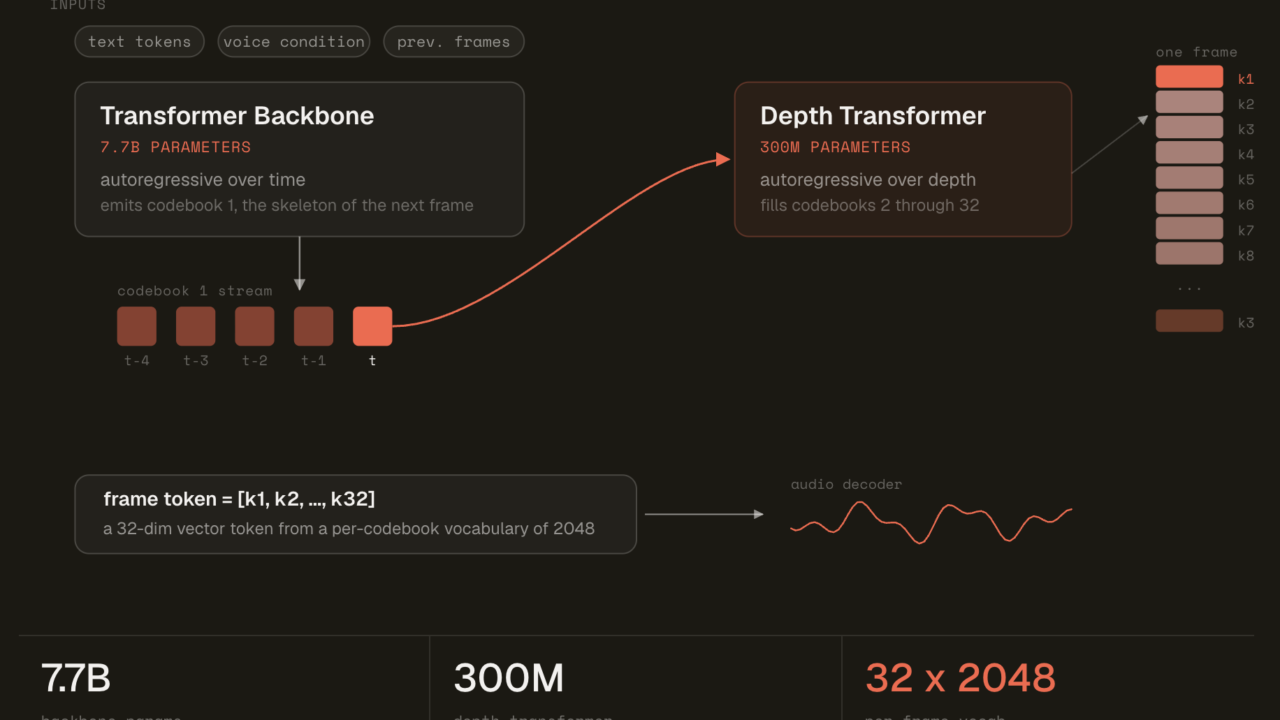
- The architecture is a Llama 3.2-style backbone paired with a smaller audio decoder, generating Mimi audio codes.
What Happened
Miso Labs officially launched MisoTTS, a new text-to-speech model distinguished by its 8-billion-parameter scale and open-weights distribution. The model’s core innovation lies in its ability to produce emotive speech by interpreting not only written text but also existing audio context. This dual input mechanism allows MisoTTS to adapt its output tone and style, responding to the nuances of a speaker’s existing voice or a desired emotional register. The release makes this sophisticated technology available to a wider audience, fostering innovation in voice AI applications.
Technically, MisoTTS is built upon an RVQ Transformer architecture, drawing inspiration from the Sesame CSM framework. It integrates a Llama 3.2-style backbone, known for its efficiency in handling large language tasks, with a specialized, smaller audio decoder. This combination enables the model to convert text and audio context into Mimi audio codes, which are then synthesized into speech. The model operates with a text vocabulary of 128,256 tokens and employs 32 audio codebooks, supporting a maximum sequence length of 2,048 tokens. Default inference for MisoTTS runs in torch.bfloat16, optimizing for both performance and computational efficiency.
A significant performance claim accompanying the MisoTTS release is its low inference latency. Miso Labs states that the model achieves a latency of
. This figure positions it as substantially faster than several established competitors; for instance, ElevenLabs is cited at 700ms and Sesame at 300ms. Such a reduction in processing time is critical for applications requiring real-time audio generation, opening new possibilities for interactive AI systems and conversational interfaces. The open-weights approach further encourages rapid development and experimentation within the AI community.
Why It Matters
The introduction of MisoTTS with its open-weights model signifies a pivotal moment for the text-to-speech industry and the broader AI community. By making an 8-billion-parameter emotive TTS model freely accessible, Miso Labs is democratizing access to advanced voice synthesis capabilities. This move lowers the barrier to entry for developers and researchers who previously might have been constrained by proprietary models or the immense computational resources required to train such large systems from scratch. The ability to condition speech generation on both text and prior audio context represents a significant leap in creating more natural and contextually aware AI voices.
For businesses, MisoTTS could fundamentally alter the economics and possibilities of integrating voice AI. Companies can now experiment with and deploy highly expressive voice interfaces without the licensing costs associated with closed-source, enterprise-grade solutions. This fosters greater innovation in customer service, content creation, education, and accessibility tools. The claimed
latency is particularly impactful, enabling truly real-time conversational AI experiences that feel more fluid and human-like. This speed advantage could redefine user expectations for AI interaction, moving beyond noticeable delays that often disrupt natural dialogue flow.
Furthermore, the use of residual vector quantization (RVQ) to expand the sonic range without increasing the parameter count addresses a fundamental scaling challenge in speech synthesis. This technical approach allows for richer, more varied vocal outputs while maintaining computational efficiency, which is crucial for deploying large models in diverse environments. The open-weights model also encourages community-driven improvements and fine-tuning, potentially accelerating the pace of innovation beyond what a single commercial entity could achieve. This collaborative development model often leads to more robust, versatile, and ethically considered AI applications.
Industry Impact
MisoTTS is set to create ripples across multiple sectors within the AI and technology landscape. Its open-weights nature empowers a wider range of developers, from independent creators to startups, to build sophisticated voice applications without the substantial upfront investment typically associated with high-quality TTS. This could lead to a proliferation of innovative uses in areas like personalized audiobooks, dynamic podcast generation, virtual assistants with emotional range, and advanced accessibility tools for individuals with speech impairments. The availability of such a capable model could also reduce reliance on a few dominant commercial providers, fostering a more competitive and diverse market.
The content creation industry, spanning media, entertainment, and e-learning, stands to benefit significantly. Imagine highly personalized educational content where an AI tutor adapts its vocal tone based on a student’s engagement, or audio dramas where character voices convey nuanced emotions generated on the fly. The claimed
latency for competitors like ElevenLabs highlights the potential speed advantage of MisoTTS. This speed is crucial for live broadcasting, real-time gaming, and interactive simulations where even slight delays can break immersion. Customer service and call centers could also see a transformation, with AI agents capable of responding with greater empathy and contextual understanding, improving overall customer satisfaction.
From a research perspective, MisoTTS provides a powerful open platform for exploring new frontiers in speech synthesis. Researchers can now dissect, modify, and build upon an 8-billion-parameter model, accelerating advancements in areas like cross-lingual voice transfer, emotional speech generation, and robust noise reduction. The model’s Llama 3.2-style backbone and RVQ implementation offer valuable insights into efficient scaling strategies for multimodal AI. This democratized access to state-of-the-art technology will likely spur academic and industrial collaboration, pushing the boundaries of what is possible in human-computer interaction and audio AI.
Analysis
The release of MisoTTS represents a strategic entry into the increasingly competitive field of emotive text-to-speech, particularly through its commitment to open weights. While many advanced TTS models remain proprietary, Miso Labs’ decision to open-source an 8-billion-parameter model immediately positions it as a significant contributor to the public AI infrastructure. This approach echoes the success seen in large language models where open-source alternatives have driven rapid innovation and widespread adoption. The model’s capacity to draw context from both text and prior audio is a critical feature, moving beyond static voice generation to more dynamic, responsive, and natural-sounding speech. This contextual awareness is key to bridging the uncanny valley often associated with synthetic voices.
Technically, the RVQ Transformer architecture, inspired by Sesame CSM and featuring a Llama 3.2-style backbone, showcases a thoughtful engineering strategy. Residual vector quantization effectively tackles the “vocabulary size problem” by allowing for a broader range of sonic expressions without incurring the prohibitive computational costs of scaling a single, flat vocabulary. This design choice is fundamental to achieving high-quality, expressive output while keeping the model’s footprint manageable for a wide array of deployment scenarios. The pairing of a robust language model backbone with a specialized audio decoder further optimizes the pipeline for both linguistic understanding and acoustic fidelity, creating a synergistic effect that enhances overall performance.
The claimed inference latency of
is a headline-grabbing figure that, if consistently achieved in real-world applications, could redefine expectations for real-time TTS. Comparing this to ElevenLabs’ 700ms and Sesame’s 300ms, MisoTTS presents a substantial advantage for applications demanding instantaneous vocal responses, such as live conversations, gaming, and interactive virtual reality. This speed, combined with emotive capabilities and open access, positions MisoTTS not merely as another entrant, but as a potential catalyst for a new wave of highly responsive and engaging AI interactions. The model’s ability to operate efficiently using torch.bfloat16 further underscores its practical deployability across various hardware configurations, making advanced TTS more accessible than ever.
Competitive Landscape
The release of MisoTTS directly impacts a text-to-speech market currently dominated by a mix of established tech giants and specialized AI startups. Companies like ElevenLabs, known for their high-quality, emotive voice generation, and Google’s various speech synthesis offerings represent the commercial frontier. MisoTTS, by offering an 8-billion-parameter model with open weights, introduces a formidable open-source alternative that directly challenges the proprietary models. The stated
latency is a crucial differentiator against competitors, particularly those like ElevenLabs and Sesame, which are cited with latencies of 700ms and 300ms respectively. This speed advantage could attract developers prioritizing real-time responsiveness in their applications.
The open-source nature of MisoTTS also places it in a different competitive category, akin to how Llama models have challenged proprietary large language models. While commercial entities invest heavily in research and development to maintain an edge, open-source projects benefit from community contributions, rapid iteration, and transparent development. This could lead to faster bug fixes, more diverse feature sets, and broader integration across different platforms. The availability of MisoTTS could pressure commercial providers to either reduce pricing, enhance features, or also consider open-sourcing certain components of their technology to remain competitive, especially for developers who prioritize flexibility and cost-efficiency.
Furthermore, MisoTTS’s ability to condition speech generation on audio context provides a sophisticated feature that is highly sought after in the market. This capability allows for more consistent voice identity and emotional continuity, which is critical for applications like voice cloning, character animation, and personalized digital assistants. While many commercial models offer similar features, MisoTTS makes this advanced functionality accessible without licensing fees. This could lead to a shift in market dynamics, where the value proposition moves from simply having a high-quality TTS model to offering competitive performance, speed, and the flexibility of open-source development.
Future Implications
Near-term (3–6 months), the availability of MisoTTS will likely lead to a surge in experimentation and rapid prototyping within the developer community. We can expect to see numerous open-source projects and independent applications leveraging MisoTTS for emotive voice generation, particularly in areas requiring low-latency responses like chatbots and interactive games. Developers will also begin fine-tuning the model for specific languages and accents, expanding its immediate utility.
Medium-term (1–2 years), MisoTTS could significantly influence the design and deployment of conversational AI interfaces. Its ability to respond to audio context will enable more natural and empathetic digital assistants, improving user experience in customer service, education, and healthcare applications. We may also see commercial entities begin to integrate or derive inspiration from MisoTTS’s architecture, potentially leading to hybrid open-source/proprietary solutions or prompting existing providers to enhance their own latency and contextual awareness features.
Long-term (3–5 years), the widespread adoption and community development around MisoTTS could establish a new benchmark for open-source text-to-speech technology, challenging the dominance of closed commercial platforms. This could lead to a more democratized AI voice landscape, where highly expressive and responsive synthetic voices are commonplace and adaptable across a vast array of applications, from personalized media creation to advanced robotics, fundamentally altering how humans interact with machines.
Actionable Insights
- Developers should immediately explore MisoTTS for projects requiring emotive and low-latency speech synthesis, particularly for real-time conversational AI.
- Businesses in content creation, e-learning, and customer service should evaluate integrating MisoTTS to enhance user engagement and personalize audio experiences without proprietary licensing costs.
- Researchers in AI voice generation should study the RVQ Transformer architecture and Llama 3.2-style backbone of MisoTTS to inform future model development and optimization strategies.
- AI product managers should consider the competitive advantage of MisoTTS’s 110ms latency when designing new voice-enabled features, prioritizing responsiveness in user interactions.
- Organizations focused on accessibility should investigate how MisoTTS’s open-weights and emotive capabilities can be adapted to create more natural and adaptable communication aids.
- Investors and analysts should monitor the adoption rate and community contributions to MisoTTS as an indicator of shifts in the broader text-to-speech market and the increasing viability of open-source AI.
What is MisoTTS?
MisoTTS is an 8-billion-parameter text-to-speech model released by Miso Labs, designed to generate expressive speech from both text and optional audio context. It features open weights, making its technology accessible to developers and researchers.
How does MisoTTS generate emotive speech?
MisoTTS conditions its speech generation on both the input text and a prior audio context. This allows the model to respond to the speaker’s tone and emotional cues, resulting in more natural and expressive synthetic voices.
What is the claimed latency of MisoTTS?
Miso Labs claims MisoTTS achieves an inference latency of 110ms. This is significantly faster than some other models, such as ElevenLabs (700ms) and Sesame (300ms), making it suitable for real-time applications.
What is residual vector quantization (RVQ) in MisoTTS?
Residual vector quantization (RVQ) is a technique used in MisoTTS to expand its sonic range without increasing the model’s parameter count. It helps avoid scaling a single flat vocabulary, allowing for richer and more varied speech output.
Why is MisoTTS being open-sourced significant?
The open-source nature of MisoTTS democratizes access to advanced text-to-speech technology, lowering barriers for developers and researchers. This encourages innovation, community contributions, and broader adoption across various AI applications.
Key Takeaways
- Miso Labs has released MisoTTS, an 8-billion-parameter text-to-speech model with open weights.
- MisoTTS generates expressive speech by leveraging both text and audio context.
- The model boasts a claimed inference latency of 110ms, significantly faster than competitors.
- Its architecture uses residual vector quantization (RVQ) to enhance sonic range efficiently.
- The open-weights release aims to democratize access to advanced emotive voice synthesis technology.
















